The section in Google Webmaster Tools that works most closely with our WordPress SEO Premium plugin, is the Crawl section. In our premium plugin, you’ll find a Webmaster Tools section, that lists all pages Google somehow did not find on your website. You can easily import these into the plugin and redirect the ones that need redirecting, so the crawl error is resolved.
The section in Google Webmaster Tools that works most closely with our WordPress SEO Premium plugin, is the Crawl section. In our premium plugin, you’ll find a Webmaster Tools section, that lists all pages Google somehow did not find on your website. You can easily import these into the plugin and redirect the ones that need redirecting, so the crawl error is resolved.
But there is more in that fourth ‘chapter’ in Google Webmaster Tools. Following our posts on Search Appearance, Search Traffic and Google Index, this article digs into for instance crawl errors and stats, finding out how Google sees your website and your XML sitemaps.
Crawl Errors
This section lists two types of errors, being site errors and URL errors. Site errors simply lists whether your DNS works, the server can easily be reached (no timeouts, for instance) and if Google can access your robots.txt file.

Google provides background information on the error (when did it occur, how often in the last 90 days). If things like this happen too much (as in more than once or twice a year without advance warning), be sure to contact your hosting company or switch hosts altogether.
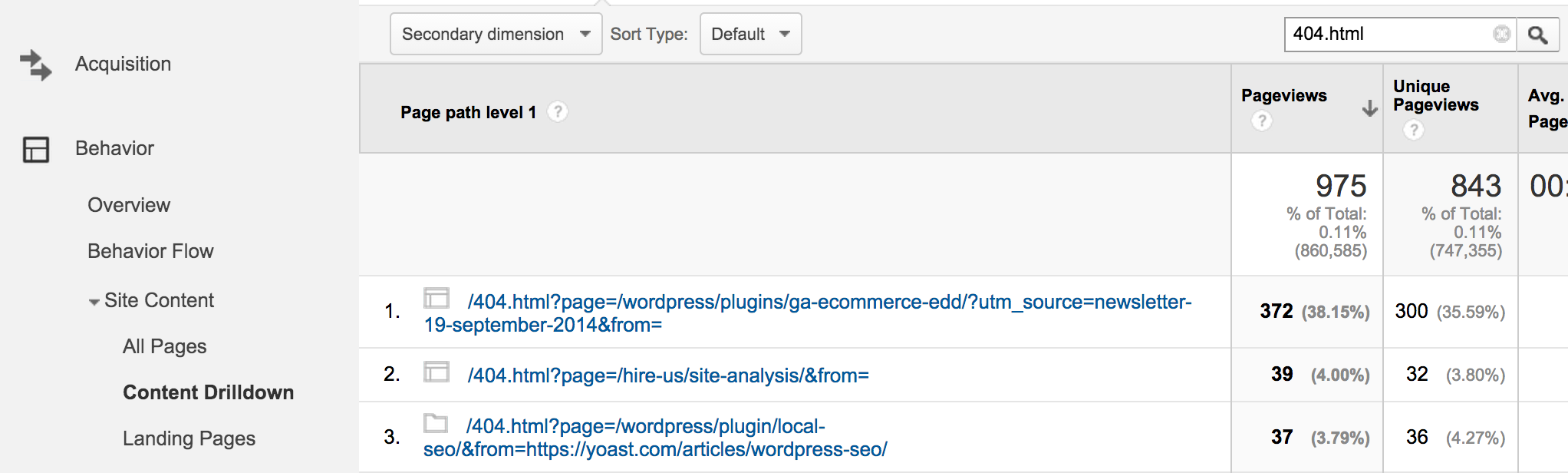
The URL error section is divided into multiple sections and subsections. First, you can check for errors that Google gets when acting a number of different devices. On for instance the desktop tab, we find the number of server errors, access denied errors and page not found errors.

Please monitor these errors, as too many errors could send a signal of low quality (bad maintenance) to Google. A 404 can be redirected, like mentioned for instance in our WordPress SEO Premium plugin, or with a bit more work straight in your .htaccess file. After that, check the checkbox in front of the URL and click Mark As Fixed (this will just make sure the list is cleaned up, it won’t do much besides that).
We have found in our reviews, that a lot of people either ignore the errors here, or forget to mark errors as fixed. This will only lead to a very long list of errors. Clean that list up now and then. If you want to check if any of these URLs are already fixed, click the link to find more information on the error and use Fetch as Google to see if the URL is now accessible for Google (or click Marked as fixed, of course).
Soft 404s
These tabs can also show Soft 404s. A soft 404 occurs, when a page as such exists, but has an empty ‘content area’. Let me elaborate on that. Google does a fine job on locating content on a page. It understands your header, sidebar, footer and content area. That also means that you can have a fully packed sidebar and footer, Google will still return a Soft 404 when the content area is empty. And by empty we also mean a category page with no posts, or any other page stating there is no content available. Or a page that just says 404 Not Found and returns a 200 OK server response anyway (happens more often than you think). This also occurs when you would for instance link an internal search page that just doesn’t return any results. There is no page, but an almost empty page is returned anyway.
Although the server will return a 200 OK message for that page, Google will consider it a (Soft) 404. You don’t want these pages on your website for a number of reasons. For one, these pages are obviously not very user-friendly. But besides that, Googlebot will have to go over all these pages for no reason at all (as they lack content), which will prevent your site from being crawled in an efficient way. After all, you don’t want Googlebot to spend time trying to see what’s on all these non-existing pages. Either add content to these pages or noindex them completely. In case of an empty category or tag page, consider removing the category or tag. You’re not using it anyway.
Smartphone visits
For your smartphone visits, Google also tests for faulty redirects and blocked URLs. A blocked URL is a page that is blocked for Googlebot-mobile for smartphones in robots.txt. Simply check if these are intentionally blocked and otherwise change robots.txt to allow access.
Faulty redirects occur when a page redirects to “an irrelevant landing page instead of the equivalent, smartphone-optimized version of the desktop page”. That could for instance be a redirect to your homepage instead of a redirect to the exact same page on your mobile site. Check the question mark next to labels in Google Webmaster Tools for more information on the terminology in Google Webmaster Tools, by the way. These explanations really come in handy, sometimes :)
Lastly, there can also be a tab for News at URL sections. That shows crawl errors for Google News content. Of course that is only for News sites. See the Google News requirements to see if your website qualifies at all for Google News, otherwise don’t bother looking for this tab.
In the end, you’ll just want this to be the only text in the Crawl Error section:

Crawl Stats
This is your handy overview of Googlebot activity on your website. It shows you the pages it crawled per day, the number of bytes downloaded per day and the time spent downloading a page. Depending on the number of pages of your website, this might be handy information.

We think this is great for trend watching. If you have made changes to your site structure, robots.txt or for instance added XML sitemaps for the very first time, that should show in the provided graphs.
In case these stats show a drastically declining line, of even a flat line at zero, there’s probably something really wrong with either the website (robots.txt might be blocking Googlebot), or your server (it could be down, for instance). Again, monitor this.
Fetch as Google
As mentioned, in case of any crawl errors, you should look into what happened and why. One of the tools Google Webmaster Tools provides, is a way to view your website as Google does. You can fetch a page as Google. You could either click the link at Crawl Errors and click the Fetch as Google link in the pop-up, or go to the Fetch as Google section in Google Webmaster Tools to enter an URL manually:

Note that in the image above, all rendered pages have been rendered quite a while ago – perhaps these already can be fetched the right way – so visit them to check this and perhaps even do a refetch. In the image, we see three different kinds of statuses (these go for both Fetch and Fetch and Render commands):
- Partial: The page can be partially rendered, as some elements are probably not displayed as intended or not at all, for instance because you are blocking CSS or JS in your robots.txt file. If you click the line with the partial status in the overview, you’ll actually be taken to a snapshot of how Google rendered your page. On that page, Webmaster Tools will also tell you which resources it could not get, so you’ll be able to fix this.
- Not Found: The page can’t be found. This might be because a redirect isn’t set yet in case of an URL / structure change, or perhaps you simply deleted the page (server returns a 404 error).
- Unreachable: Googlebot didn’t have the patience to wait for your website to load (make it faster), or your server simply replied that it could not allow the request for the URL.
Of course there are more. Other statuses you might find here are:
- Complete: That’s the one you want. Google managed to crawl the entire page.
- Redirected: Either the server or your website itself (HTML/JS) told Google to visit another URL.
- Not authorized: Your server tells Google that URL access is restricted or has been blocked from crawling (server returns a 403 error).
- DNS not found: Perhaps you entered the wrong URL? The domain name seems incorrect.
- Blocked: Your robots.txt tells Google to bugger off.
- Unreachable robots.txt: Google can’t reach your robots.txt at all. More on testing the robots.txt below.
- Temporarily unreachable: Either the server took too long to reply or too many consecutive requests were made to the server for different URLs.
- Error: An error occurred when trying to complete the fetch (contact Webmaster Tools product support in this case).
By clicking the URL, you can see the rendered page as seen by both Googlebot and a visitor, so you can make an judgement on the impact of the blocked file:

In this case, the impact is clearly low.
Robots.txt Tester
Last week, Joost explained a lot about the Partial status at Fetch as Google in his post WordPress robots.txt Example. You really need to make sure your robots.txt is in order.
By the way, you might be wondering if you really need that robots.txt file. Actually, you don’t. If you think Google should crawl all sections on your server, you could leave it out. The Robots.txt tester will return this message in that case:

In the Robots.txt tester, Google will show the robots.txt you are using and tell you any and all issues Google finds:

That’s a warning: Googlebot ignores that crawl delay. If for some reason you do want to set a crawl delay, please do so using the gear icon in the upper right in Google Webmaster Tools (at Site Settings > Crawl Rate – new crawl rates are valid for 90 days). Please note that this is not how often Google visits your site, it’s the speed of Googlebot’s requests during the crawl of your website.
![]()
Hm. And what do you want Google to do with /wordpress/wp-includes/? By the way, like in this example, we see a lot of webmasters adding a link to the sitemap to their robots.txt. No problem, but why not simply add that in Google Webmaster Tools instead? More on that later.
![]()
This is another syntax not understood. Comments in robots.txt can be done using hashtags instead:

Works like a charm.

Ouch. The horror. Google could not find a user-agent in this robots.txt – but it’s there, right? It’s actually preceded by a space, and that immediately triggers a ‘syntax not understood’ for the robots.txt test.
It doesn’t mean all 20 restrictions in that robots.txt will be ignored, by the way. This seems to be a strict test, but Google is very capable of filtering that space. Google actually encourages whitespace for readability. But strictly speaking, it shouldn’t be in there.
Visit Webmaster Tools for even more information on the robots.txt syntax.
Test allowed / disallowed
One more thing. When you want to test whether a page or directory on your site can or can not be reached by Googlebot, or for instance Googlebot-News or Googlebot-Mobile, you can test that as well in this section, right below the robots.txt code.
If we take the last example above, and test the /Tests/ part of it, you’ll see that that indeed can be indexed if we follow the strict rules of the Robots.txt tester:
![]()
Although the text ‘Allowed’ is green, it’s not a good thing that this directory can be indexed. As mentioned, the space isn’t allowing Googlebot in this case, according to the Google search result pages:
![]()
Feel free to add any insights on this particular issue in the comments below.
If you test a page or directory and find that it is blocked like this:
![]()
the test tool will also tell you what line in your robots.txt is causing this:
![]()
All in all, if you are using your robots.txt actively, make sure your robots.txt will do what you intended it to do. The Robots.txt tester will help you a lot.
Sitemaps
It doesn’t matter if you are setting up a new WordPress site, or have just installed our WordPress SEO plugin: activate XML sitemaps and remove any other plugin that does this as well. Don’t forget to redirect the old XML sitemap, probably at /sitemap.xml, to ours at /sitemap_index.xml. If you experience any issues, check our knowledge base.
Having said that, if you have a proper XML sitemap, go to Google Webmaster Tools and test and add it at Sitemaps. Unfortunately Google doesn’t allow you to add a tested sitemap immediately after testing. Yes, this is my feature request, Google ;)

These sitemaps can be added manually, but perhaps Google already found some. These are listed on the All tab:

We often get questions about image XML sitemaps. Images are actually already inserted by our plugin in for instance post-sitemap.xml and page-sitemap.xml:

Back to Google Webmaster Tools. First you want to make sure /sitemap_index.xml contains all the content types you want Google to index. Please check the XML sitemap section in our plugin and see if you can exclude any post types or taxonomies from the XML sitemaps; this usually already fixes a lot of warnings and errors. Especially on shops, where sitemaps can be created for shipping classes and cloth sizes, for instance, that would be my first advice.
Second, you add the /sitemap_index.xml, which will be added immediately, along with any sitemaps listed on that sitemap. If for some reason that sitemap still contains content you’d rather not have indexed, simply change that in our plugin and resubmit it in Google Webmaster Tools. Note that you can manually add and delete sitemaps, but the ones that are automatically added for instance by an index sitemap, can only be deleted by a resubmit.
I thought about adding a list of possible errors and warnings to this article as well. Seriously. But when I found that Webmaster Tools actually added internal navigation on their Sitemap Errors page, it seemed to make sense to simply link that page.
Common warnings are warnings about Google not being able to reach a page, due to a long response time or for instance an URL included in an XML sitemap, but excluded in robots.txt.
Errors vary from invalid date formats to sitemaps not being found (a 404 on your sitemap is never a good idea). A sitemap can also be empty, or a required tag can be missing.
Indexed versus submitted content
Another thing you might wonder about is the difference between index and submitted content types (pages, video, images). These are the red and blue bars in this section. The red bar (indexed types) is usually a bit lower, as Google isn’t crawling your entire site at once. Time is precious, so Google spiders a (large) number of pages at a time, but if your site structure goes a gazillion levels deep, chances are Googlebot isn’t getting to these deepest pages in a crawl. It’s not that Google bookmarks where they end up and start from there the next time it crawls your website. This emphasizes the need for a good internal link structure, well formatted sitemaps and things like that.
URL Parameters
Let’s start with Google’s warning here:
Use this feature only if you’re sure how parameters work. Incorrectly excluding URLs could result in many pages disappearing from search.
If you are using URL parameters, like the default s for WordPress search, please check this section. When discussing this post with Joost, he told from experience that f.i. in case of a site migrations, things might go terribly wrong if this isn’t done properly.
In this section, you can tell Google how to handle your parameters. When clicking Add a Parameter, you’ll get a pop-up with these options:

I entered the ‘s’ for search, and have to decide on that parameter to affect page content or just change the way content is displayed on the page. Google respectively calls this passive and active URL parameters. Active parameters can for instance be used for sorting, pagination and sometimes even translations or categorization. Passive parameters are usually for tracking or referrals, like Magento’s SID (session ID) and Google’s own utm_source.
Now if you feel the parameter “changes, reorders or narrows page content”, and pick Yes in the above select box, you’ll be presented with four more options. You can set here how you want Google to handle the parameter:
- Let Googlebot decide: a general option if you’re not sure what to choose here.
- Every URL: Every URL using this parameter is an entirely new page or product.
- Only URLs with specified value: This will indicate to Google that you only want URLs crawled with a specific value for this parameter and forget the rest, for instance to avoid duplicate content due to sorting options.
- No URLs: Don’t crawl pages with this parameter at all. Avoiding duplicate content is a reason to use this one as well.
Note that instead of using URL parameters for option 3 and 4, you could also set the right canonical on all of these pages.
TL;DR?
Sorry to disappoint you. There is no Too Long; Didn’t Read in this. In the previous posts on Google Webmaster Tools, we have already emphasized the importance of checking your site now and then, or monitoring it actively. Google Webmaster Tools helps a lot with that, and this is one of the longest (and in my opinion most interesting) sections in Google Webmaster Tools.
Feel free to drop any addition or question related to this section in the comments. Looking forward to it!
This post first appeared as Google Webmaster Tools: Crawl on Yoast. Whoopity Doo!
 This is already the third post in our Google Webmaster Tools series. Last week we’ve written about the
This is already the third post in our Google Webmaster Tools series. Last week we’ve written about the 







 Following Thijs’ article on
Following Thijs’ article on